

Introduction – The Use Case
This POC involves a job aggregator website, a platform that collects and presents job opportunities from multiple institutions in a single location for job seekers. Traditionally running such a website requires a team. A content creator to draft detailed job posts and a graphic designer to produce engaging thumbnails or images. This manual process is time consuming and also demands constant attention to make sure posts are timely and visually appealing.
My approach demonstrates how AI infused automation can streamline this entire process replacing manual effort while delivering content faster and more efficiently.
The platform in the question receives job postings in three primary formats.
- Image based job posts
- PDF documents
- Web URLs (Job postings from career pages)
This solution allows site administrator to submit these inputs directly into a n8n pipeline that generates a ready to publish website posts, including a thumbnail image, in under 30 seconds. This automation dramatically reduces the time and effort compared to traditional manual publishing.
An added advantage is the mobility. Admin can perform submissions and approvals from their phones whether commuting or standing in line at a grocery store. The only requirements are the Discord or WhatsApp mobile app to submit inputs and the Jetpack app to approve draft posts. My testing has confirmed successful post creation across these scenarios.
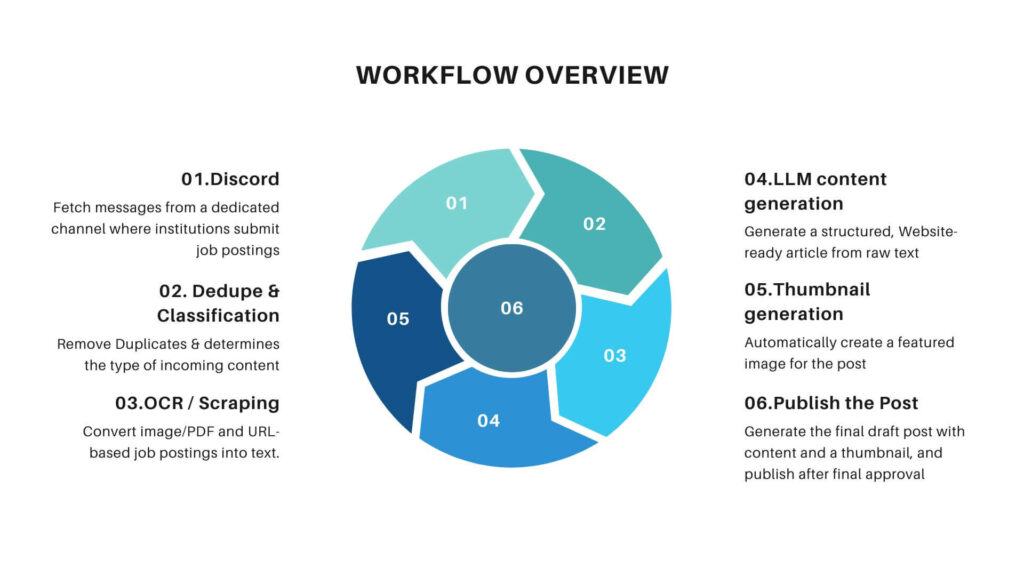
High Level Workflow Architecture
The pipeline uses n8n workflow automation which integrated to Discord, OCR services, LLMs, and WordPress as the CMS. The workflow converts raw job inputs into fully structured posts complete with SEO friendly content and thumbnails.
Node by Node Walkthrough
Lets break down the entire n8n workflow into its individual components explaining the role and operation of each node in sequence. I will show how a job post travels from a simple entry in Discord through data extraction, content generation, and thumbnail generation to publish the article in the website (WordPress).
N8N-WF- Schedule Trigger
The workflow begins with a Schedule Trigger node that runs at regular intervals typically every few seconds. Its role is to keep the pipeline active and responsive by checking for new messages in the designated Discord channel. Instead of relying on manual initiation this automation make sure that job posts are captured almost instantly after they appear.
- Discord Node (Get Source)
Once the Schedule trigger initiate the workflow the Discord node connects to a dedicated channel where admin share job advertisements. It retrieves the message content with job post images, PDFs and URLs while also recording details such as the sender’s name, timestamp, and message ID.
This node acts as the bridge between human input and automated processing turning every message into a structured data object.
- Remove Duplicates
To maintain workflow integrity and prevent the reposting of the same content this step involves a deduplication check. This node compares each new message against previously processed entries using either message IDs or content hashes.
Only unique messages are passed forward. This small but critical step make sure that the automation handles each job post once even if a message is accidentally resent on Discord.
- Code Node (Input Classification)
At this stage the workflow evaluates what type of input it has received. A code function inspects each message and categorizes it as an image, a PDF, a URL, or an unsupported format. This classification determines which branch of the workflow will handle the input next.
The logic is straightforward. An image is sent to the OCR route, a PDF to the text extraction route, and a URL to the scraper route. Anything else is marked as unsupported and rerouted for notification node which yells at the admin.
- Router Node
The Router node acts as the decision maker of the pipeline. Based on the classification from the previous code node it directs the data down the correct processing path. This branching mechanism keeps each workflow segment clean and purpose built.
The image, PDF, and URL branches each contain their own set of specialized nodes that extract and process job information, while unsupported inputs are gracefully handled by a separate notification path.
- a. Image Branch – OCR Extraction
When the input is an image this branch engages an OCR service to extract readable text. The image is first pre processed before being sent to an external OCR API. The output is plain text showing the content of the job post. This conversion allows image adverts which are often shared as posters or social media flyers to be transformed into editable text that the Content Cooker node can later structure into a proper article.
- b. PDF Branch – PDF Text Extraction
PDF files are handled by a separate extraction path. The workflow first checks whether the file contains selectable text. If not it applies OCR to read text from embedded images. Once the raw text is extracted the script cleans it by normalizing line breaks removing random whitespace. The outcome is a clear block of job information suitable for the next stage of content generation.
- c. URL Branch – Web Scraping
If the admin shares a career post link instead of a document the URL branch comes into play. This part of the workflow sends an HTTP request to the specified page and parses the returned HTML. The scraper isolates the relevant job title, description, and application link while discarding unrelated site elements such as navigation menus or ads.
The extracted data is then converted to clean markdown producing a well structured text body for later use by Content Cooker Node.
- Unsupported Content Branch
Sometimes a input may contain media types the system cannot process such as spreadsheets or short text fragments without context.
Rather than failing silently the workflow uses this branch to humiliate the admin through a Discord reply. The message simply tell the input could not be handled and ask the admin to resend the job post in a supported format.
- Text Validation (Code + If Node)
After text extraction the workflow verifies whether the content is enough for creating a job article. A validation script checks the text length and looks for essential details like the job title, location, and application deadline.
If the content meets the criteria it is sent to the next step. Otherwise the workflow notifies the admin that the post lacks enough information.
- Content Cooker (LLM Node)
This is the creative core of the workflow. The Content Cooker node sends the validated job text to an LLM (got-4.1-mini) with a detailed prompt instructing it to generate an SEO friendly job article.
The model structures the data into clearly defined fields as title, excerpt, formatted content, tags, and also choose a suitable category from a predefined set of job categories. The result is a neatly organized JSON output that mirrors what a human web content creator would write.
- Structured Output Parser
Before publishing the workflow performs one more safeguard. This node checks that all required fields from the LLM output are present and correctly formatted. It validates the JSON schema, to make sure the article includes a title, category, excerpt, and body content. If the data passes this inspection, the post is approved for submission. This make sure the consistency across all posts and eliminates the risk of malformed entries breaking the site layout.
- Thumbnail Generation
To complete the visual side of things, the workflow generates a featured image automatically. I built a separate, self hosted image generation API built with Node.js, Express, and the Canvas and Sharp libraries to generate the thumbnail automatically. This lightweight service accepts structured data such as job title, company name, and category ID through a secure REST endpoint protected by an API key.
Each request loads a matching background template (already saved in the project folder) based on the category, then uses the Canvas library to render text layers dynamically. The script automatically handles font registration, word wrapping, and layout spacing to make sure consistent typography and alignment. Sharp is used at the end of the process to optimize and encode the final PNG image with high clarity and minimal file size.
Below you can see the sample template image on the left and automatically generated image on the right side.


- Upload Thumbnail to CMS
The generated image is then uploaded to the WordPress media library through the REST API. WP doesn’t let the thumbnail or featured image to be uploaded on the same time publishing the post. We have to upload the thumbnail beforehand.
After uploading the thumbnail the upload node returns the image media ID or URL which the system associates with the upcoming post as its featured image. This automated handoff make sure that each article published through the pipeline appears complete with both text and visuals.
- Create Draft Article
With all content and media ready the workflow compiles the final post and creates a draft entry in WP backend. The draft includes the title, excerpt, formatted content, tags, category, and featured image reference.
Leaving the post as a draft allows an admin to review (Man in the loop) the generated content before it goes live.
- Discord Notification
After the draft is successfully created the workflow sends a confirmation message to Discord. This notification includes the job title and a preview link to the draft allowing the administrator to review it quickly from the mobile app. From there the post can be opened in Jetpack (WP) app for approval and publishing.
The entire process, from receiving the job post to creating a publish ready article takes less than 30 seconds, dramatically reducing the workload compared to manual editing.
Results and Proof of Concept
To validate the workflow we ran three separate tests, each representing a common way the admin receives job information, an image post, a PDF document, and a career article. Each test was executed using the n8n pipeline, and all outputs were published to the website within 30 seconds.
Test 1 – Image based Job Post
The admin uploaded the image through Discord. The workflow extracted text content using the OCR node and generated a short description through the content cooker node, and created a branded thumbnail through the image generation API.
Input Image
Website Post
MAL-HR-ATest 2 – Document based Job Post
The admin dragged the document into Discord. The PDF parser extracted structured text, and the content cooker node summarized it into a reader friendly format. The thumbnail generator node created a relevant thumbnail.
Input PDF
PB-HOR-inputWebsite Post
PB-HORTest 3 – Career Page Article
The admin paste the job article URL from a live website to the discord and the workflow scraped the title, description, and metadata using the web scraper node. The content cooker node then refined the content for clarity and the thumbnail generator produced a matching banner.
Input URL (Webpage as a PDF)
NCINGA-PEWebsite Post
NCINGA-P-DCNote:
The webpages are converted to a PDF for display purposes because the career posts may be removed from the original sources.
Source Disclaimer
The example posts used in this proof of concept belong to their respective companies and organizations. They are included only for demonstration purposes to showcase the workflow’s capability and not for commercial or promotional use. I do not claim ownership, rights, or credit for any of the example job postings, images, or materials shown. If any organization featured in these examples has concerns or wishes to have their content removed, please contact me directly, and I will promptly take action.
Efficiency and Impact
The POC showed a remarkable improvement over the manual posting process. All three posts were created and published in under 30 seconds entirely through the automated workflow without opening a laptop or editing anything manually.
The entire process from pushing a job post, (Image/PDF or URL) to Discord and to publishing formatted article live on website was handled on a mobile device. This demonstrates how automation can replace hours of repetitive work with a single seamless action.
Broader Applications
While this POC was built for job aggregation the same workflow model can be adapted across many industries and applications. With minor changes to the extraction and formatting steps the workflow can support mass news aggregation, event listings, tender publications, or press release syndication. Any process that relies on collecting structured or semi structured content from multiple sources and publishing it to a website or CMS platform can benefit from this workflow design.
By replacing manual content development, image preparation, and website formatting with automated workflows organizations can achieve dramatic cost reductions and faster turnaround times. Teams that once required separate roles for data entry, writing, and design can now manage the entire publishing process by a single person from a single interface or even a mobile device. This shift not only lowers operational costs but also enables near real time content delivery.
What’s Next
The workflow is now running successfully in a test period on a popular job aggregator site in Sri Lanka and will soon move into full production. The results so far show consistent reliability, accuracy, and minimal maintenance effort confirming that the concept is ready for real world deployment.
As the next step I plan to publish a technical article series explaining how to deploy n8n on an Oracle Cloud instance, integrate GPT based AI models and connect to WordPress and Discord. These guides will walk through each stage of setup and configuration so you can build similar automation pipelines for your own use.
If you are interested in following this project or learning how to build your own automation workflows subscribe to my newsletter to get updates when each article is released.